Praktický příklad: analýza a vizualizace dat
Praktický příklad analýzy datasetu MovieLenses (1M).
Data obsahují 1 milión hodnocení 4000 filmů od 6000 uživatelů z webové databáze MovieLenses ze začátku roku 2003. Data
jsu rozdělena do tří tabulek movies.dat, ratings.dat, users.dat. Podrobnosti naleznete
v souboru README.txt
# ukázka users.dat
1::F::1::10::48067
2::M::56::16::70072
3::M::25::15::55117
# ukázka movies.dat
1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
# ukázka ratings.dat
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275Nešim cílem bude zjistit ve kterých filmech se nejvíce liší hodnocení můžu a žen.
import pandas as pd
# upravime defaultni zobrazeni
pd.options.display.max_rows = 10
# nacteni dat
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']
users = pd.read_table('users.dat', sep='::', header=None, names=unames, engine='python')
rnames = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_table('ratings.dat', sep='::', header=None, names=rnames, engine='python')
mnames = ['movie_id', 'title', 'genders']
movies = pd.read_table('movies.dat', sep='::', header=None, names=mnames, engine='python')
# slouceni dat (jedna tabulka je vyhodnejsi)
data = pd.merge(pd.merge(ratings, users), movies)
# prumerne hodnoceni filmu dle pohlavi
mean_ratings = data.pivot_table('rating', index='title', columns='gender', aggfunc='mean')
# zjistime pocty hodnoceni jednotlivych filmu
ratings_by_title = data.groupby('title').size()
# vybereme pouze filmy, ktere maji vice jak 250 (nahodna hodnota) hodnoceni
active_titles = ratings_by_title.index[ratings_by_title >= 250]
# hodnoceni pouze u vybranych filmu
mean_ratings = mean_ratings.loc[active_titles]
# priklad: nejlepe hodnocene zenami
top_female_ratings = mean_ratings.sort_values(by='F', ascending=False)
# vypocitame neshodu v hodnoceni
mean_ratings['diff'] = mean_ratings['M'] - mean_ratings['F']
# filmy ktere se libi F a ne M
sorted_by_diff = mean_ratings.sort_values(by='diff')
sorted_by_diff[:10]
# filmy ktere se libi M a ne F
sorted_by_diff[::-1][:10]
# filmy s nejvetsi neshodou nezavisle na pohlavi
# lze snadno zjistit pres std (standard deviation)
rating_std_by_title = data.groupby('title')['rating'].std()
# opet omezime na nejvice hodnocene filmy
rating_std_by_title = rating_std_by_title.loc[active_titles]
# vysledek
rating_std_by_title.sort_values(ascending=False)[:10]
Zadání
-
úkol 1
Zjistěte, které filmy jsou dle databáze MovieLenses nejoblíbenější. Do souboru
best_movies.csvuložte prvních 10 filmů ve formátucsv. -
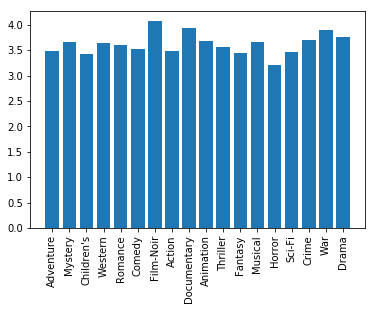
úkol 2
Zjistěte průměrné hodnocení (rank) jednotlivých žánrů. Výsledek vykreslete formou sloupcového grafu. Například: